一月在索信达控股实习了,这是一家金融AI大数据解决方案提供公司。一般是和银行合作。我实习的部门是AI研发中心,同事个个都是高学历(人均博士?)。
在实习的过程中我主要干了两件事:
- 命名实体识别(NER)
- 异常检测
命名实体识别 Named-entity recognition
NER要做的是将自然语言里的“实体”识别出来,当然实体有非常多种,如人名,地名,组织,时间等等。我负责的部分是时间识别。
纯时间短句
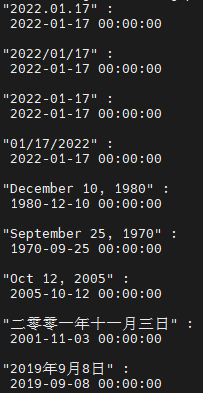
对于纯时间短句,有一个非常好用的Python库dateparser。这个库支持多种语言,并且支持用户添加词典。基本上可以稳定将各类时间实体统一转化成Python datetime 对象
自然语言句子
对于自然语言句子内的时间则需要首先进行分词,中文分词我用了Jieba库,配合飞桨Paddle。
"内蒙古大中矿业股份有限公司(以下简称“公司”)于 2021 年 5 月 28 日召开了第四届董事会第十六次会议和第四届监事会第九次会议,审议通过了《关于使用部分闲置募集资金进行现金管理的议案》,同意公司在保证募集资金投资项目建设需求的前提下,使用不超过 7 亿元闲置募集资金购买安全性高、流动性好的低风险保本理财产品,期限自第四届董事会第十六次会议审议通过之日起不超过 12 个月。具体内容详见公司 2021 年 5 月 31 日披露的相关公告。"
[('2021年5月28日', datetime.datetime(2021, 5, 28, 0, 0), (0, 0, 0), ''),
('12个月', datetime.datetime(2022, 5, 28, 0, 0), (1, 1, 1), 'Relative Date'),
('2021年5月31日', datetime.datetime(2021, 5, 31, 0, 0), (0, 0, 0), '')]可以看到,效果还是不错的。
在识别功能的基础上,我还额外实现了基于上下文的自动推测。例如“12个月”属于相对时间,并没有完整的年月日时间,程序就会自动在最近的上下文中找到提及的确定时间填充。这里可以看到,“12个月”被理解为了上文提到的2021年5月28日的12个月后,和原文相符。
当然,这一推测方式并不能完全保证准确。所以在输出中包含了推测标记和原因。如(1, 1, 1)表示年月日均为推测。
日志输出
处理日志输出主要使用了正则表达式。由于日志输出一般格式化较强,且时间格式的表达比较正式,所以正则表达式就能够很好的完成识别。
用到的表达式:
(([\[\{\(])(?:(?!\2).)+(?:[\}\]\)])) #识别各种括号中
((['" ])(?:(?!\2).)+(\2)) #识别引号和空格中Python实现
matches = re.findall('''((['" ])(?:(?!\\2).)+(\\2))''',date)
...
matches = re.findall('''(([\\[\\{\\(])(?:(?!\\2).)+(?:[\\}\\]\\)]))''',date)
...提取出的字符串依然交给dateparser库处理,结果也是不错的。
{"Url":"http://item.jd.com/11381983.html","EndDate":"2018-04-25T13:46:50.345631+08:00","FieldValueDic":{"IsDeleted":"False","AF1":"9787543699762"}} :
[('2018-04-25T13:46:50.345631+08:00', datetime.datetime(2018, 4, 25, 13, 46, 50, 345631, tzinfo=<StaticTzInfo 'UTC\+08:00'>)), ('9787543699', datetime.datetime(2280, 2, 27, 2, 8, 19))]
Jun 15 12:12:34 2018 combo sshd(pam_unix)[23406]: check pass; user unknown :
[('Jun 15 12:12:34 2018', datetime.datetime(2018, 6, 15, 12, 12, 34)), ('2018', datetime.datetime(2018, 1, 31, 0, 0)), ('15', datetime.datetime(2022, 1, 15, 0, 0))]
[Sun Dec 04 04:52:15 2005] [error] mod_jk child workerEnv in error state 7 :
[('Sun Dec 04 04:52:15 2005', datetime.datetime(2005, 12, 4, 4, 52, 15), (0, 0, 0)), ('04:52:15', datetime.datetime(2022, 12, 31, 4, 52, 15)), ('04:52:15', datetime.datetime(2022, 1, 31, 4, 52, 15)), ('2005', datetime.datetime(2005, 12, 31, 0, 0)), ('Dec', datetime.datetime(2022, 12, 31, 0, 0)), ('Dec', datetime.datetime(2022, 12, 31, 0, 0))]
REQ UP 1527579194 POST / {"Content-Length":"61926",xxxxxxxxxx} :
[('1527579194', datetime.datetime(2018, 5, 29, 15, 33, 14)), ('1527579194', datetime.datetime(2018, 5, 29, 15, 33, 14))]
REQ UP 15275791948097993 POST / {"Content-Length":"61926",xxxxxxxxxx} :
[('1527579194', datetime.datetime(2018, 5, 29, 15, 33, 14))]由于使用了多种正则表达式,可能出现重复识别的结果。对于这个问题我使用了一个未经严格论证的猜想:越长的成功识别的字符串越可能是正确的。
需要注意的一点是虽然dateparser库可以识别10+位数的unix时间戳,但实际上对于超过一定长度的时间戳会忽略。如果有需要提高覆盖率的可以在预处理阶段截取纯数字的前十个数进行识别。(如最后一个例子)
异常检测 (outlier detection)
异常检测是大数据金融里一个常见的问题。利用各类算法精准识别如盗刷,系统故障等异常对保持服务质量至关重要。而异常检测在数据科学中也是老课题了,各种算法非常多,各有优势和劣势。我的工作就是对各类算法进行测试,对比之中的优劣。
这里主要使用了pyod库,这是一个整合了大多数现有的异常检测算法的库。利用这个库可以比较方便的对同一个数据集运行各种异常检测算法来对比。
数据集选用了kaggle上的这个数据集:https://www.kaggle.com/mlg-ulb/creditcardfraud
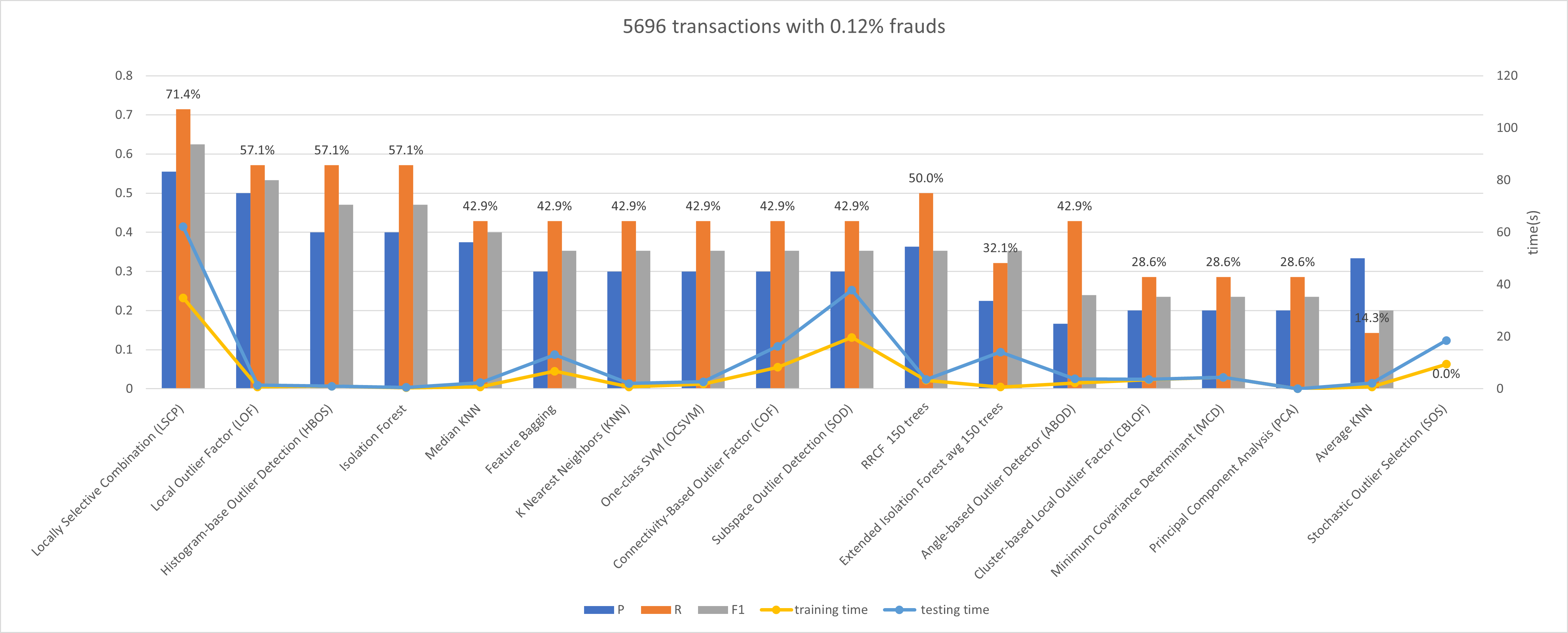
原数据集有超过21万条记录,我的电脑实在是难以处理,因此我随机采样了一些数据进行实验。
评判标准采用的准确率,查全率和F1,由于客户更加看重查全率,所以图上标注的是查全率百分比,以F1降序排列。
可以看到,对于这个数据集,LSCP的查全率和准确率都最高,但耗时也最长,在更大的数据集上这一差距会指数级放大。而排名稍后的LOF,HBOS,Isolation Forest则有着更快的速度,这在大规模数据上是很好的优势。
但这个实验仅限于这一数据集,而根据数据集维度,异常比例的不同可能会有表现上的变化
例如,在另一个数据集的测试上MCD和OCSVM有更好的表现。
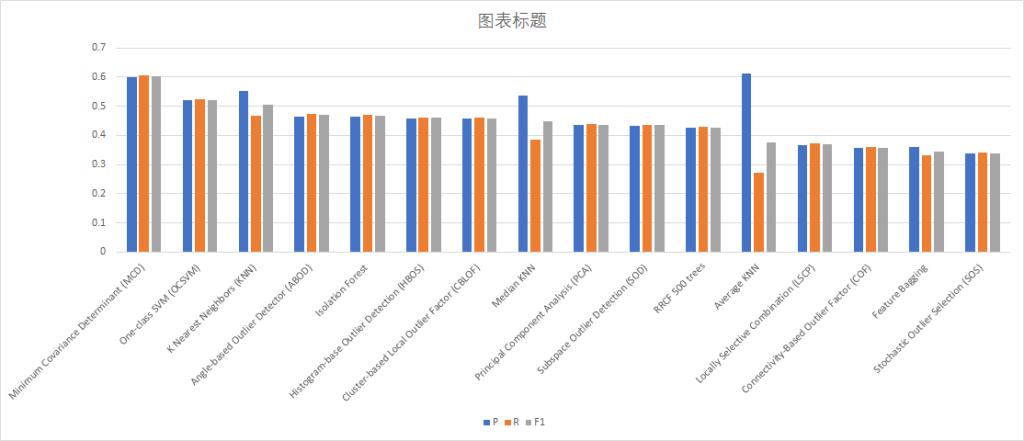
另外,每个算法各自的参数也可能对结果产生影响,实验中没有进行对算法的微调。
博主您好,我本来今日是想自建邮局来的,故前往购买域名,但发现此域名已经先被您先注册了,所以来到您的博客看看。
实话实说我感觉还挺神奇的。